从未如此简单:10分钟带你逆袭Kafka!
|
副标题[/!--empirenews.page--]
【51CTO.com原创稿件】Apache Kafka 是一个快速、可扩展的、高吞吐的、可容错的分布式“发布-订阅”消息系统, 使用 Scala 与 Java 语言编写,能够将消息从一个端点传递到另一个端点。
图片来自 Pexels 较之传统的消息中间件(例如 ActiveMQ、RabbitMQ),Kafka 具有高吞吐量、内置分区、支持消息副本和高容错的特性,非常适合大规模消息处理应用程序。 Kafka 官网: Kafka 主要设计目标如下: 以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 TB 级以上数据也能保证常数时间的访问性能。 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒 100K 条消息的传输。 支持 Kafka Server 间的消息分区,及分布式消费,同时保证每个 Partition 内的消息顺序传输。 同时支持离线数据处理和实时数据处理。 支持在线水平扩展。 Kafka 通常用于两大类应用程序: 建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。 构建实时流应用程序,以转换或响应数据流。 要了解 Kafka 如何执行这些操作,让我们从头开始深入研究 Kafka 的功能。 首先几个概念: Kafka 在一个或多个可以跨越多个数据中心的服务器上作为集群运行。 Kafka 集群将记录流存储在称为主题的类别中。 每个记录由一个键,一个值和一个时间戳组成。 Kafka 架构体系如下图:
Kafka 的应用场景非常多, 下面我们就来举几个我们最常见的场景: ①用户的活动跟踪:用户在网站的不同活动消息发布到不同的主题中心,然后可以对这些消息进行实时监测、实时处理。 当然,也可以加载到 Hadoop 或离线处理数据仓库,对用户进行画像。像淘宝、天猫、京东这些大型电商平台,用户的所有活动都要进行追踪的。 ②日志收集如下图:
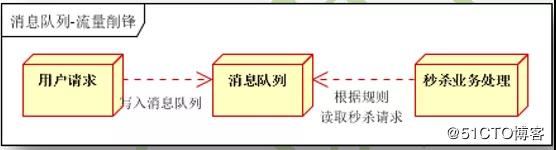
③限流削峰如下图:
④高吞吐率实现:Kafka 与其他 MQ 相比,最大的特点就是高吞吐率。为了增加存储能力,Kafka 将所有的消息都写入到了低速大容量的硬盘。 按理说,这将导致性能损失,但实际上,Kafka 仍然可以保持超高的吞吐率,并且其性能并未受到影响。 其主要采用如下方式实现了高吞吐率: 顺序读写:Kafka 将消息写入到了分区 Partition 中,而分区中的消息又是顺序读写的。顺序读写要快于随机读写。 零拷贝:生产者、消费者对于 Kafka 中的消息是采用零拷贝实现的。 批量发送:Kafka 允许批量发送模式。 消息压缩:Kafka 允许对消息集合进行压缩。 Kafka的优点如下: ①解耦:在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。 消息系统在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。 这允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。 ②冗余(副本):有些情况下,处理数据的过程会失败。除非数据被持久化,否则将造成丢失。 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。 许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。 ③扩展性:因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。不需要改变代码、不需要调节参数。扩展就像调大电力按钮一样简单。 ④灵活性&峰值处理能力:在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见;如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。 使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。 ⑤可恢复性:系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。 ⑥顺序保证:在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。Kafka 保证一个 Partition 内的消息的有序性。 ⑦缓冲:在任何重要的系统中,都会有需要不同的处理时间的元素。例如,加载一张图片比应用过滤器花费更少的时间。 消息队列通过一个缓冲层来帮助任务最高效率的执行,写入队列的处理会尽可能的快速。该缓冲有助于控制和优化数据流经过系统的速度。 ⑧异步通信:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。 Kafka 于其他 MQ 对比如下: ①RabbitMQ:RabbitMQ 是使用 Erlang 编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP,SMTP,STOMP,也正因如此,它非常重量级,更适合于企业级的开发。 同时实现了 Broker 构架,这意味着消息在发送给客户端时先在中心队列排队。对路由,负载均衡或者数据持久化都有很好的支持。 ②Redis:Redis 是一个基于 Key-Value 对的 NoSQL 数据库,开发维护很活跃。 虽然它是一个 Key-Value 数据库存储系统,但它本身支持 MQ 功能,所以完全可以当做一个轻量级的队列服务来使用。 (编辑:源码网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |